Sketch2Sound
Controllable Audio Generation via Time-Varying Signals and Sonic Imitations
Hugo Flores Garcíaio, Oriol Nietoi, Justin Salamoni, Bryan Pardoo and Prem Seetharamani
iAdobe Research, oNorthwestern University
read the paper on arxiv
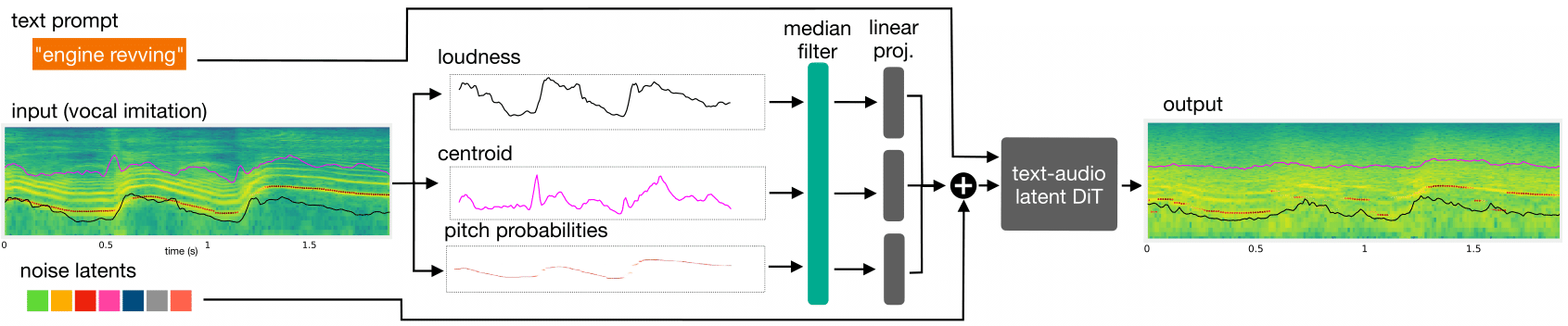
We present Sketch2Sound, a generative audio model capable of creating high-quality sounds from a set of interpretable time-varying control signals: loudness, brightness, and pitch, as well as text prompts. Sketch2Sound can synthesize arbitrary sounds from sonic imitations (i.e., a vocal imitation or a reference sound-shape).
Sketch2Sound can be implemented on top of any text-to-audio latent diffusion transformer (DiT), and requires only 40k steps of fine-tuning and a single linear layer per control, making it more lightweight than existing methods like ControlNet. To synthesize from sketchlike sonic imitations, we propose applying random median filters to the control signals during training, allowing Sketch2Sound to be prompted using controls with flexible levels of temporal specificity.
We show that Sketch2Sound can synthesize sounds that follow the gist of input controls from a vocal imitation while retaining the adherence to an input text prompt and audio quality compared to a text-only baseline. Sketch2Sound allows sound artists to create sounds with the semantic flexibility of text prompts and the expressivity and precision of a sonic gesture or vocal imitation.
watch our demo video:
Fig. 1 - Listening Example
| text prompt | input (sonic imitation) | output (sketch2sound) |
|---|---|---|
| “car racing” | 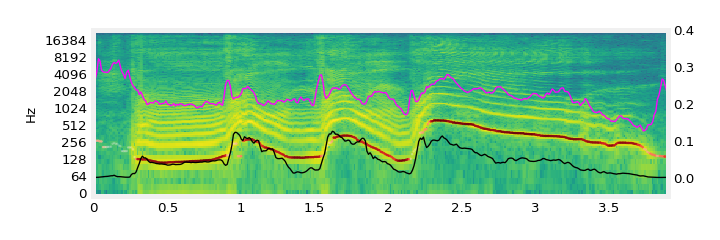 |
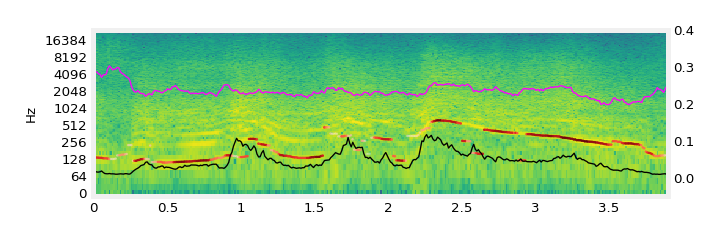 |
Fig. 3 - Control Curve Semantics
| text prompt | input (sonic imitation) | output (sketch2sound) |
|---|---|---|
| “forest ambience” | 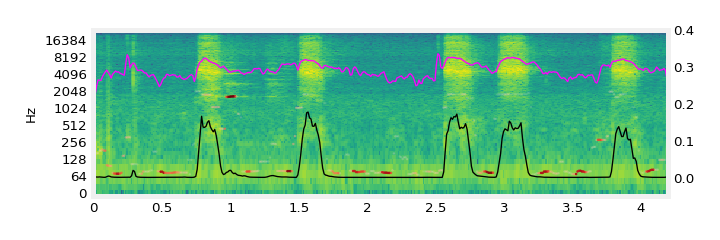 |
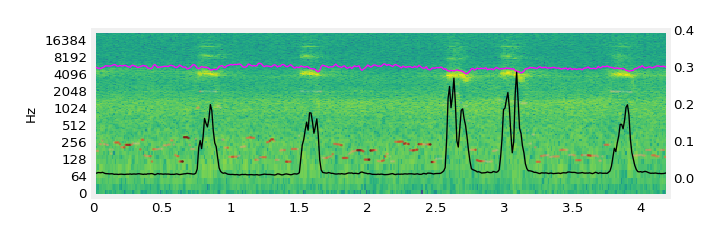 |
When prompted with “forest ambience”, bursts of loudness in the controls become of birds without prompting the model to do so.
| text prompt | input (sonic imitation) | output (sketch2sound) |
|---|---|---|
| “bass drum, snare drum” | 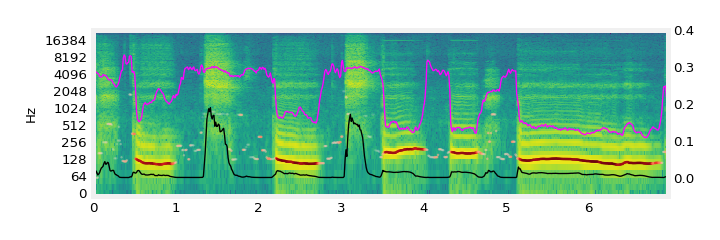 |
 |
With “bass drum, snare drum”, the model places snares in unpitched areas and bass drums in pitched areas.
demo video - guitar sonic imitations:
a note on how these examples and demos were chosen:
The examples in the demo video were chosen to illustrate Sketch2Sound’s capabilities as a tool for creating sound effects synced to video through vocal imitations. Though the outputs themselves were not cherry picked, the text prompts were chosen according to how visually compelling they would be, and how well we could imitate their sounds with our voice.