research
Sketch2Sound
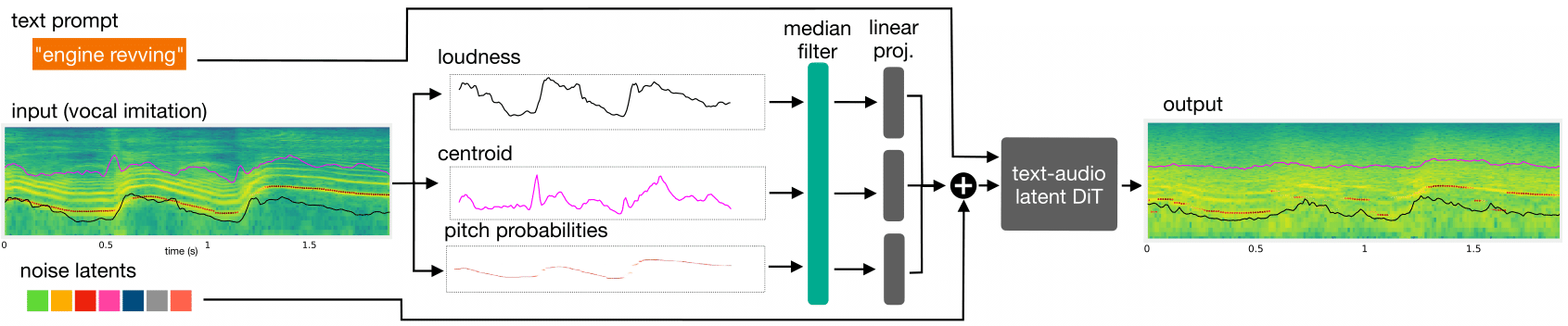
Sketch2Sound is a generative audio model capable of creating high-quality sounds from a set of interpretable time-varying control signals: loudness, brightness, and pitch, as well as text prompts.
Sketch2Sound can synthesize arbitrary sounds from sonic imitations (i.e., a vocal imitation or a reference sound-shape).
Check out our demo video, paper and website: sketch2sound website

The Rhythm In Anything (TRIA)
Led by my labmate Patrick O’Reilly, TRIA (The Rhythm In Anything), takes as input two audio prompts – one specifying the desired drum timbre, and one specifying the desired rhythm – and synthesizes drum beats that follow the rhythm prompt, while keeping the timbre prompt (i.e. playing the desired rhythm with the desired timbre).
Chicago Creative Machines
I had the joy of giving the inaugural talk + performance for the Chicago Creative Machines series at ESS Chicago on Feb. 25, 2024. I talked about my compositional work with vampnet, using the mouth as the interface for a generative model, showed an 8ch composition for voice and vampnet, and played a solo set of instrumental music with.
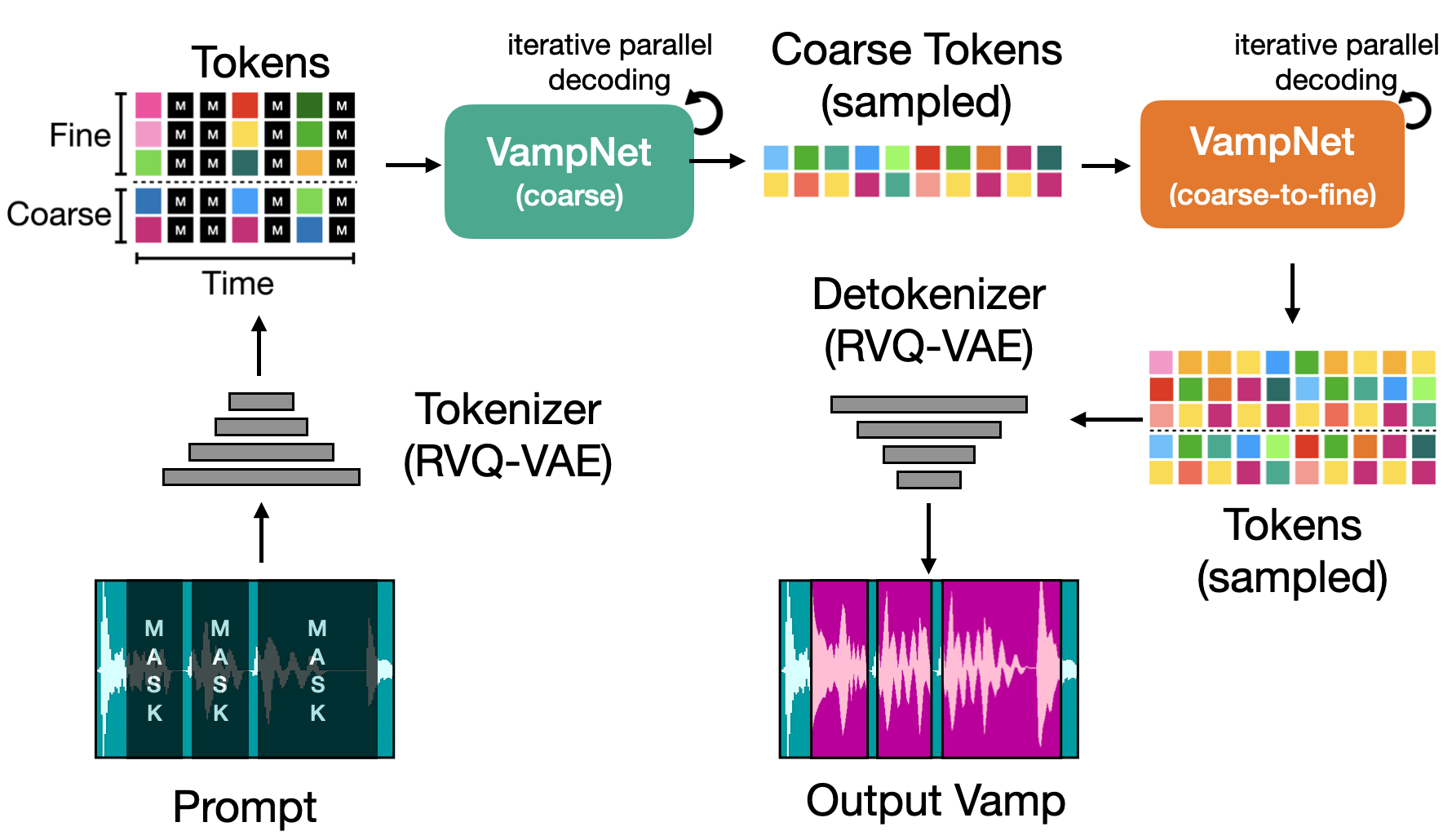
VampNet - Music Generation Via Masked Transfomers
VampNet is a generative model for music that uses a masked token modeling technique to perform music generation and compression. We proposed new ways to prompt a generative model with music by masking out parts of some input with a meaningful mask structure, and have VampNet fill in the missing parts with new musical content. Check out the paper and listen to audio samples!
ISMIR 2022 Tutorial on Few-Shot and Zero-Shot Learning for MIR
Yu Wang, Jeong Choi and I gave a tutorial during ISMIR 2022 on few-shot and zero-shot learning centered around music information retrieval tasks. In this tutorial, we cover the foundations of few-shot//zero-shot learning, build standalone coding examples, and discuss the state-of-the-art in the field, as well as future directions.
The tutorial is available as a jupyter book online.
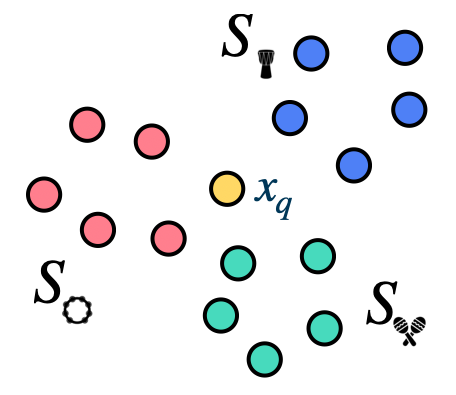
Deep Learning Tools for Audacity
Aldo Aguilar, Ethan Manilow and I made a software framework that lets deep learning practitioners easily integrate their own PyTorch models into Audacity. This lets ML audio researchers put tools in the hands of sound artists without doing DAW-specific development work, which is often a long and arduous process in itself.
Learn more about it in our project page :).
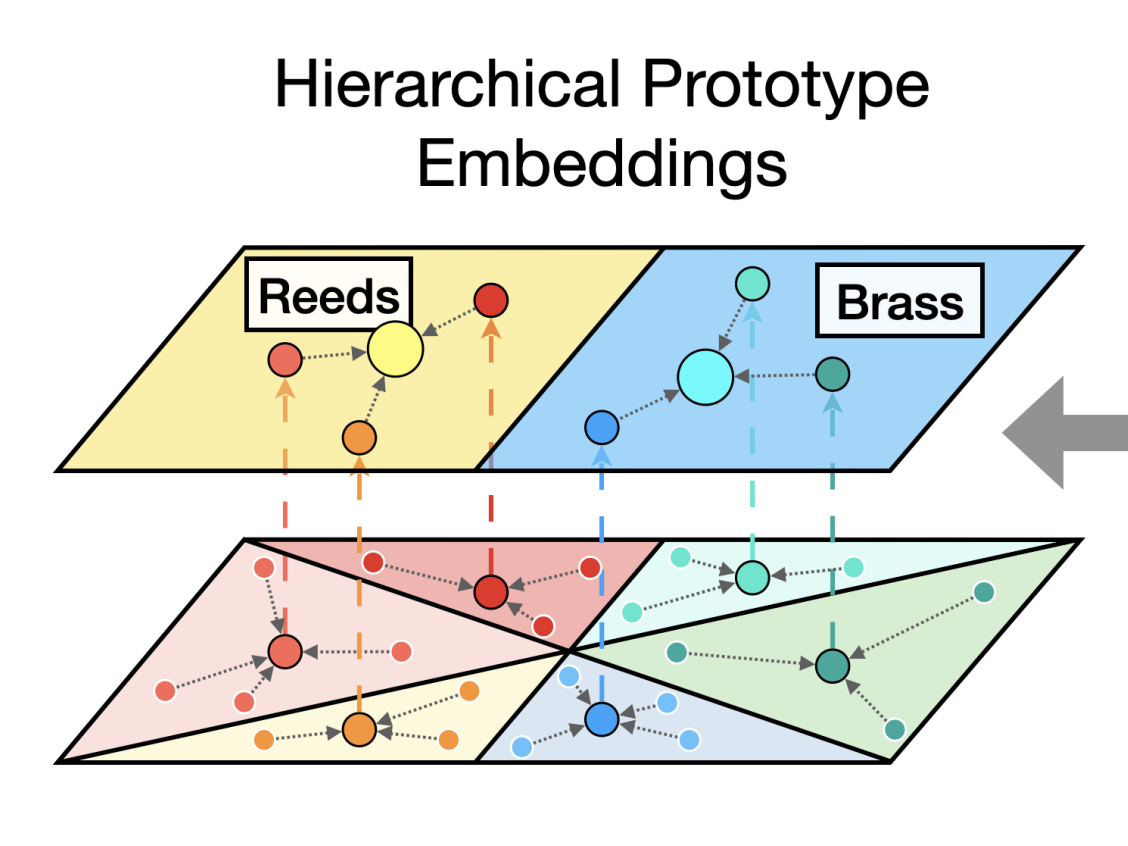
Leveraging Hierarchical Structures for Few-Shot Musical Instrument Recognition
In this work, we exploit hierarchical relationships between instruments in a few-shot learning setup to enable classification of a wider set of musical instruments, given a few examples at inference. See the supplementary code on github.
update: this work won the Best Paper Award at ISMIR 2021! :)
watch the poster video!